Autonomous Microservices - Outbox Pattern
In a microservice architecture the most of its complexity is in the consistency of the data. Very often the main questions are:
- “What’s the best way to communicate microservices so that one gets data from the other?”
- “How to expose in a single endpoint the relationship between resources?”
- “How to deal with 2PC(Two Phases Commit)/Saga?”
Throughout this article, I will try to answer those questions.
Well, before we get into the nuances of the solution to the questions above, let’s understand what’s the real problem.
The context
When using an architecture based on microservices, usually the first fact that comes to mind is to separate services by domain, that is, taking e-commerce as an example, we could have a microservice for Users and another one for Orders. So, let’s imagine this scenario.
The Problem
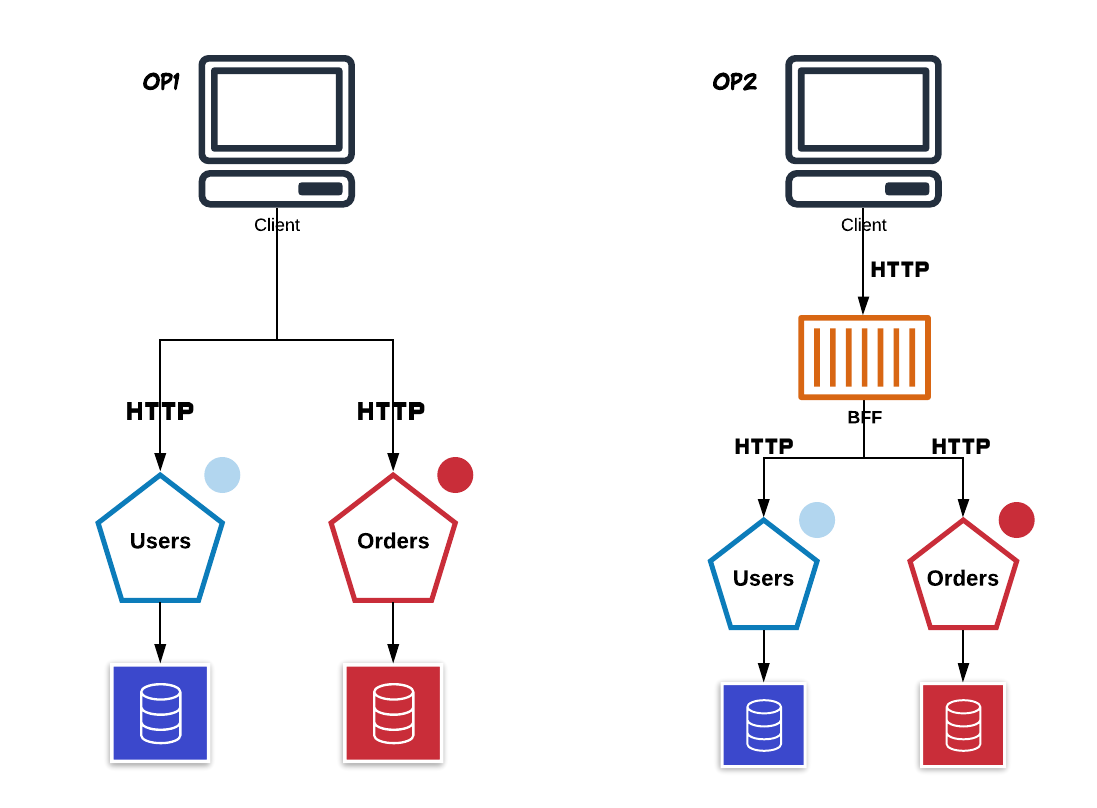
Imagine an situation where is needed return the relationship between users and orders. Normally, there are two ways:
- Make two requests(one to capture users and the other one to capture each person’s orders).
- Create a BFF (Backend For Front-end) that makes the above step.
However, what if our business rule is that for each new user we need to create a new order?
“Well, but it’s easy! Just propagate an event in the message broker when creating a user”
Good! But, if the process of creating an order fails, the new user should be removed as well…
“Just use the Saga Pattern“
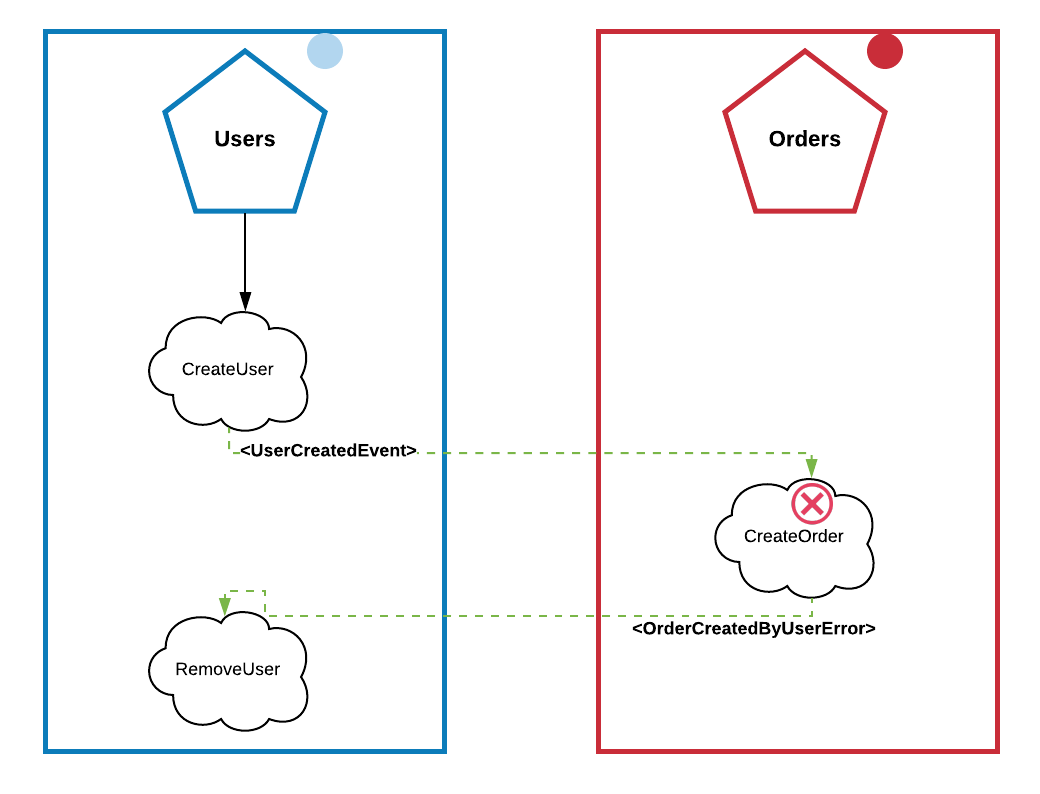
Well, if you needs to merge other services under this rule, your architecture will be exponentially complex. There is Outbox Pattern for that; over the course of this article, we will understand why dealing with eventual consistency is good and allows you to scale in an architecture that have tons of business rule.
Normally, microservices have their own data store, in our context, Users have their database and Orders too. However, in the above example we deal with dual write, that is, the simple creation of users can lead to possibles inconsistencies. The problem is that we aren’t able to have a shared transaction that spans the service’s database and the message broker as well, as the latter cannot be analyzed in distributed transactions. Therefore, in unfortunate and possible circumstances may happen that the new user is created in the database, but the message has not sent in the message broker (for example, due some network problem). The inverse is true also, we could sent the message to the message broker, but we are unable to store the user in the database.
Both situations are undesirable; this can cause no order to be created for a user apparently successfully created. Or the order is created, but there is no user correlated for that.
Remember: One of the main concepts of microservices is the resilience, so if your service depends of others services to work properly, there is no microservices architecture, but a microlithic architecture as I affectionately call it.
CAP Theorem
This Theorem states that is impossible for the distributed data storage provide simultaneously more than two of the following three guarantees:
- Consistency
- Availability
- Fault tolerance partition
Consistency
A guarantee that each node in a distributed cluster will return to the most recent write. Consistency refers to each customer having the same data view. There are several types of consistency models. CAP consistency (used to prove the theorem) refers to linearizability or sequential consistency, a very strong form of consistency.
Availability
Each node that does not fail returns a response to all requests for reading and writing within a reasonable period of time. To consider available, all nodes (em both sides of a network partition) must returns in a small time period.
Fault-tolerant partition
A system that is “Fault-tolerant partition” can sustain any network fail that doesn’t result in a complete network issue. The data is replicated between the nodes/network to keep the system active by intermittent interruptions. To deal with modern distributed systems, the partition tolerance is not an option, is a necessity. Therefore, we should choose between consistency and availability.
Choosing
Consistency + Availability: Usually used in systems that needs a strong consistency and high availability, also called an optimistic approach, since they assume that the writing NEVER fails.
Consistency + Partition Fault-tolerant: Systems that opt for this strategy, need to give up of availability. There is a word, quite important in this context, called: Consciousness. In CP type systems, if there is a written partitioning - as mentioned earlier, it can be rejected/denied.
Availability + Partition Fault-tolerant: Is used when the main necessity is to have availability and scalability, therefore, given up the consistency dealing with the famous Eventual Consistency, it means, leaving your data to be consolidated through nodes indefinitely.
YouTube Use Case
The YouTube needs lie to to their users, and I’ll explain the reason. When we deal with a huge amount of data as YouTube has, speaking about scalability is one of the hardest tasks, following the CAP Theorem, we should opt for Availability and Partition Fault-tolerant for sure. I mean, imagine how to centralize the data in a unique place or wait until eventually some error appears on the user screen? Therefore, let’s go to some obvious options:
- Share the same data store for every application – And that will be your problem (the biggest one).
- Let a single server processing the requests of getting the data – And this server will be the bottleneck.
- Keep more than one data server, doing the data eventually be consolidated between all servers. – Winner.
This the reason that if two people join in a top/hot video at the same time will be the visualization count with different numbers (of course, if they were passed by different servers through the load balancer).
“How to deal with eventual consistency? If I need of latest data?”
Well, as previously said, there is no free lunch. Everything depends on the architectural problem to be solve. The users domain will always have the current data as if it were the most recent, after all it does not know other domains. Therefore, if for any reason will be necessary to get the data in realtime, could be that this approach is not good to solve your specific problem – Normally is not necessary the true realtime; it’s not scalable.
Eventual Consistency
“Eventual consistency is a consistency model used in distributed computing to achieve high availability that informally guarantees that, if no new updates are made to a given data item, eventually all accesses to that item will return the last updated value. Eventual consistency, also called optimistic replication, is widely deployed in distributed systems, and has origins in early mobile computing projects. A system that has achieved eventual consistency is often said to have converged, or achieved replica convergence. Eventual consistency is a weak guarantee – most stronger models, like _linearizability are trivially eventually consistent, but a system that is merely eventually consistent does not usually fulfill these stronger constraints.”_ – Wikipedia
The idea of this pattern is that any information that the service X needs contains in its have in their own domain. In our context, let’s think that we need the user’s fullname when a Order is created, so, to Order domain the user is only a set of fullname, is now that Bounded Context comes to play.
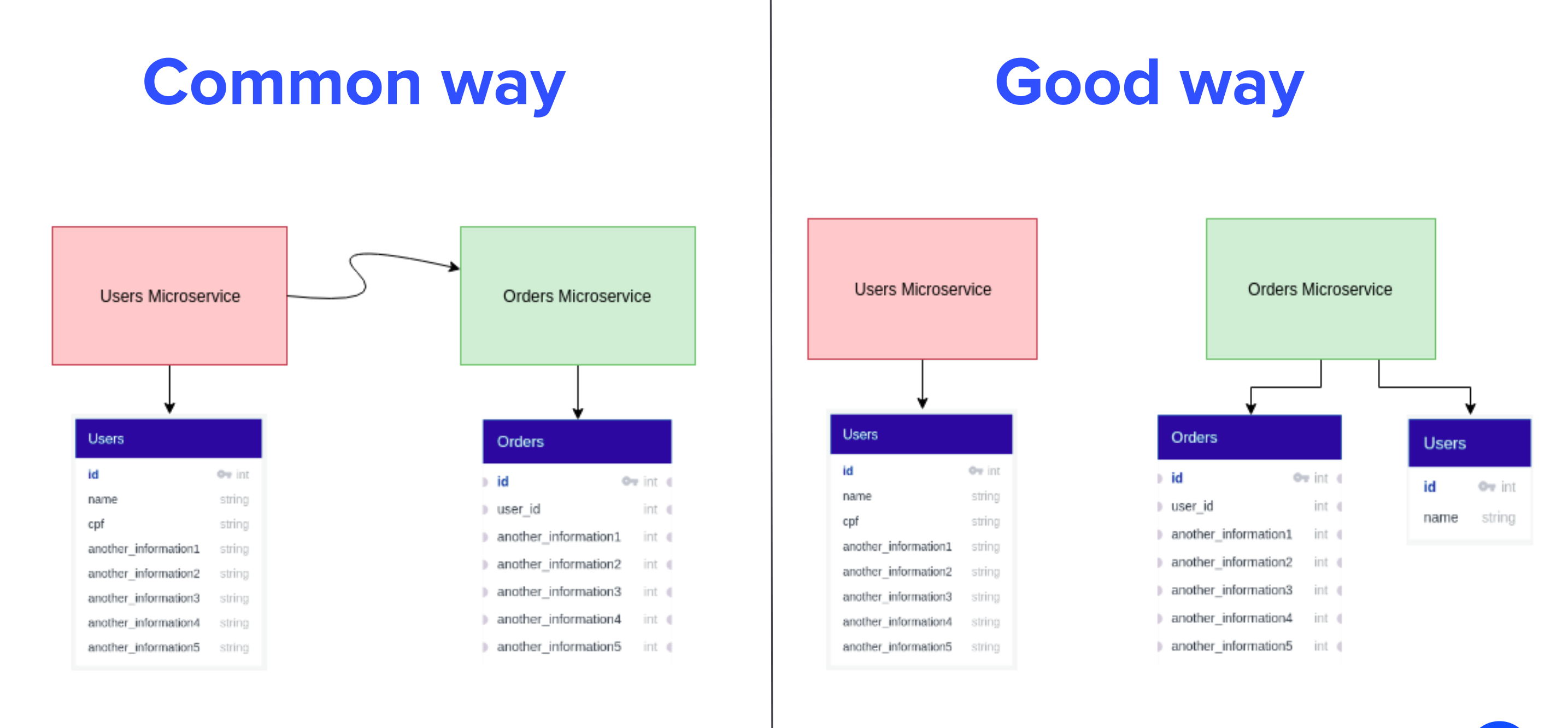
Take a look that the data will be replicated in both services (email, full_name), and this is good! We guarantee local consistency and we have local transaction instead of distribuited transaction.
Consolidating the data
We have the full idea, and now?
Now, I’ll present the infamous Debezium and its power of CDC (Change Data Capture).
The idea of Debezium is simple, it works on top of Apache Kafka, that is, imagine an insertion trigger in the database, listening for any changes in the table (depending on the configuration) and replicating them to the broker. That is, by definition we expose the data we want – Widely used a table outbox with the schema below ref
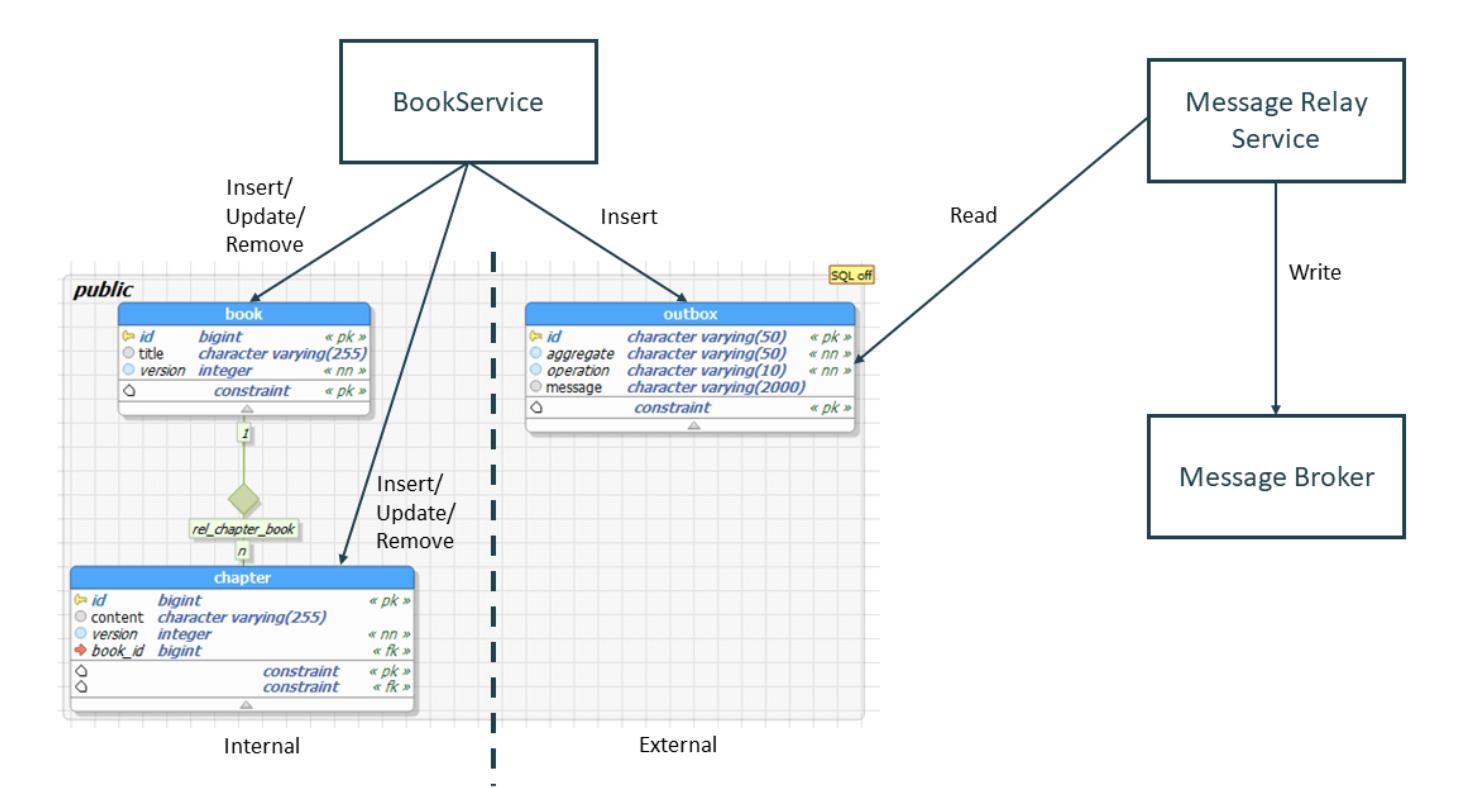
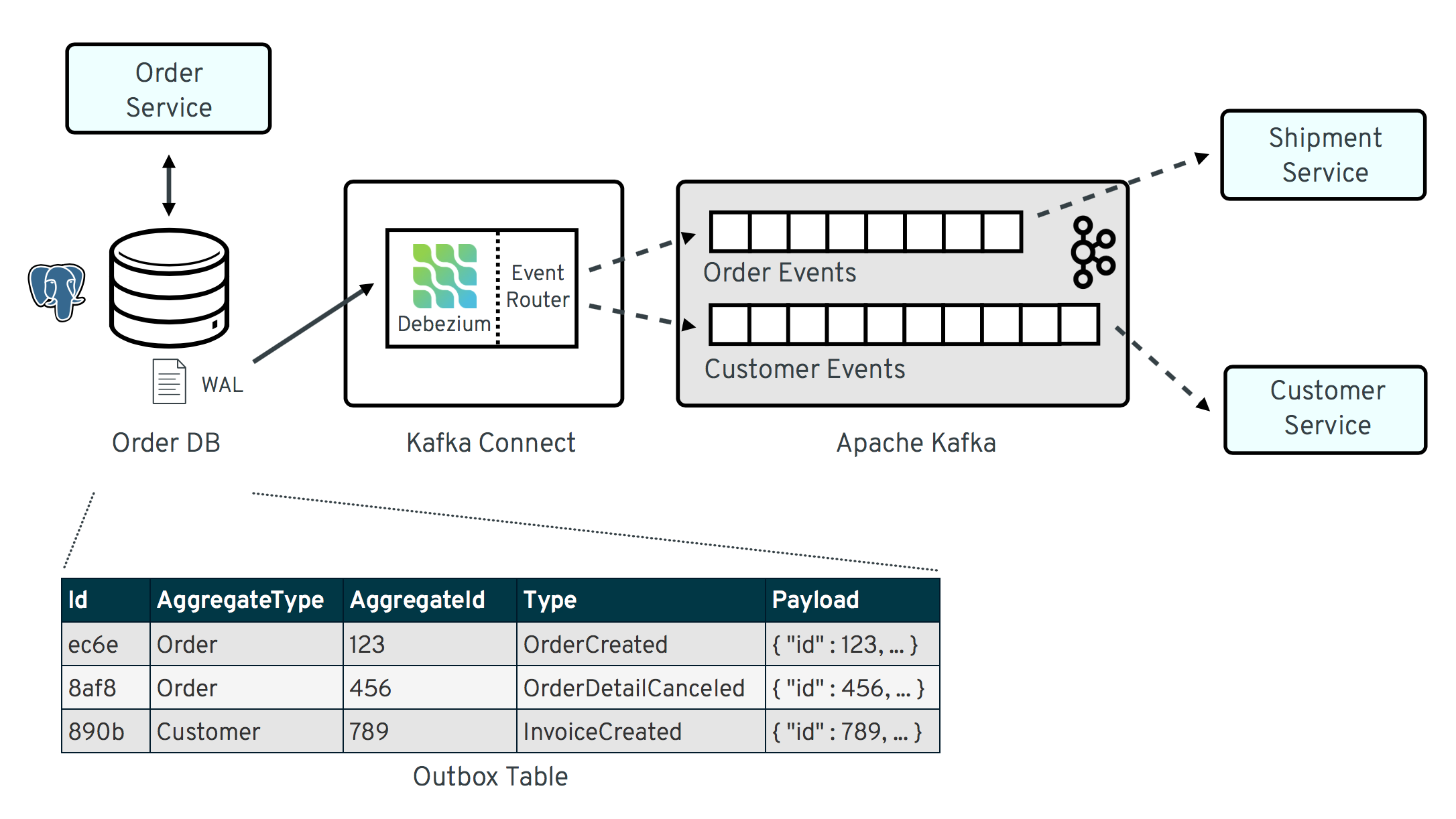
I won’t explain how Debezium does it, instead you can look to its excellent documentation.
To show in practice, I made a very simple example here just follow the instructions in the README, and voilà!
Any doubts, contact me on my social networks.