Comunicação entre microsserviços Async
Introdução ao RabbitMQ e seus feitos.

Em uma arquitetura voltada para microsserviços, dois dos seus principais conceitos chaves são: escalabilidade e resiliência. Dito isso, é bem comum que haja a necessidade dos microsserviços se comunicarem de alguma forma, seja para requisitar recursos ou baseada em Event Driven. Então, como fazer isso sem afetar diretamente a resiliência ?
Esse artigo é o primeiro de uma série que pretendo fazer sobre algumas formas de comunicação entre os microsserviços.
Primeiro de tudo, essa abordagem não é uma bala de prata, tudo vai depender do problema na qual sua arquitetura se propõe a resolver.
Uma coisa é fato, a comunicação é complexa e nesses casos a transparência é essencial. Usar os padrões corretos para realizar tal comunicação pode lhe ajudar a escalar e resolver grande parte dos problemas que virão (sim, haverão diversos problemas!). As vezes a boa e velha comunicação síncrona via HTTP pode resolver seu problema (mesmo perdendo um “pouco” em resiliência).
Neste artigo tentarei mostrar porque a comunicação via message brokers tem ganhado bastante espaço, com isso nomes como: RabbitMQ, Kafka, ActiveMQ apareceram e vem sendo amplamente usados. Especificamente neste artigo tratarei sobre RabbitMQ, mas alguns desses patterns também são usados nas outras tecnologias de messageria.
Lembrando: se sua necessidade é lidar com microsserviços com o máximo de resiliência, verifique uma arquitetura baseada em Event Sourcing.
O que é mensageria/message brokers ?
A message broker (also known as an integration broker or interface engine[1]) is an intermediary computer program module that translates a message from the formal messaging protocol of the sender to the formal messaging protocol of the receiver. — Wikipedia
Em um breve resumo, se trata de um intermediário de comunicação — Pense na logística para enviar uma carta (finja que isso ainda é usado), então de forma resumida os principais passos são:
-
Você escreve a carta.
-
Você a coloca na caixa de correio com um determinado destinatário.
-
E então a agência de correios cuidará de entregar sua carta.
Então, como sua carta será enviada e quando ela chegará você já não tem mais conhecimento sobre, você já fez seu trabalho e está “livre” para realizar as demais tarefas.
Dessa forma acontece com messagers brokers, você propaga uma mensagem em um exchange(caixa de correio) e o messager broker(agência de correios) enviará baseado em uma lógica do exchange para assim chegar no seu consumer(destinatário).
Porque isso é bom ?
Como dito anteriormente, resiliência e escalabilidade é um dos pontos chaves dessa arquitetura, imagine que você utilize uma comunicação via HTTP, se você emitir uma request diretamente ao microserviço há alguns problemas no qual você terá de lidar:
-
Baixa resiliência — Enviar uma requisição HTTP, além de latência, seu microserviço fica fortemente acoplado ao endpoint requerido, fugindo de um dos conceitos chaves dessa arquitetura.
-
Baixo escalonamento horizontal — Normalmente sua requisição será em um cluster interno (assumindo que sua arquitetura faz uso de um API Gateway) e como iria ser feito o load balancer desse evento ? No mínimo será necessário fazer um proxy + load balancer para cada microserviço ou fazer sua requisição passar pelo gateway, a grande pergunta aqui é: vale todo esse esforço? Provavelmente não.
E como isso funciona assincronamente?
Agora vamos supor a mesma situação acima porém de forma assíncrona, e os mesmos problemas relatados serão ajustados:
-
Resiliência e Baixo acoplamento — De fato, ambas palavras são fortes, e devem ser buscadas sempre que possível em qualquer aplicação. Como seus eventos serão enviados a um intermediário (RabbitMQ) será necessário somente garantir que esse serviço esteja funcionando, e como a messagem será enviada ao microserviço destinatário já não será do domínio da sua aplicação… Portanto, quanto menos souber do destinatário, mais coesa e escalável fica sua arquitetura.
-
Escalonamento horizontal — Com RabbitMQ (e qualquer outra tecnologia de messageria) é feito automaticamente um Load Balancer de suas mensagens, baseado na forma escolhida pelo exchange, por default será Competing Workers Pattern(explicarei melhor sobre esse padrão abaixo). Enfim, fato é, você consegue escalar sua arquitetura horizontalmente de forma simples e prática.
Comunicação Assíncrona
A comunicação assíncrona é amplamente usada quando não há necessidade de esperar uma resposta. Porém, há casos na qual ela se aplique, RPC é um dos patterns que há uma espera por uma resposta.
Ao esperarmos uma resposta de qualquer recurso, sua aplicação fica em standby aguardando uma resposta que pode nunca vir (dependendo do timeout, claro!) e, convenhamos…. É um disperdício deixar um hardware aguardar por algo sendo que há tanto processo que poderia ser feito, não?
Fora isso, há alguns pontos para se levar em conta quando decidir utilizar uma arquitetura assíncrona:
-
Baixo desacoplamento — Como mencinamos nos tópicos acima, desacoplamento é algo ótimo, e deixa a aplicação mais flexível.
-
Sem dependência de uma client library — Quem nunca teve de criar um SDK para utilizar nos produtos internos que requisitavam o grande monolítico chamado carinhosamente de API? Pois bem, gerenciar versões, e manter isso era um pouco problemático.
Nesse artigo, tentarei mostrar alguns dos padrões utilizados na messageria assíncrona step by step, e o resultado disso você pode encontrar aqui.
É necessario quem um serviço RabbitMQ esteja rodando, caso não tenha, basta subir esse container:
sh docker run -d -p 8080:15672 -p 5672:5672 -p 25676:25676 rabbitmq:3-management
Competing Workers Pattern
](https://cdn-images-1.medium.com/max/4000/0*sO3z1p1s_-9Nj414.png) fonte: https://blog.cdemi.io/design-patterns-competing-consumer-pattern/
fonte: https://blog.cdemi.io/design-patterns-competing-consumer-pattern/
Competing Workers Pattern ou Competing Consumers Pattern, é um pattern comumente usado em uma arquitetura de microsserviços, pois ele consiste no load balancer de mensagens de uma fila, entre os N consumers. Ou seja, escalar uma aplicação que utiliza deste pattern é muito simples.
E como isso funciona na prática?
Certo, então vamos lá! Primeiro de tudo, vamos precisar criar um producer.js que ficará responsável por emitir um evento em um exchange. Quando não definimos um exchange, e emitimos o evento diretamente na fila, ele fará o uso de um exchange default que será o caso aqui.
Vamos criar um produtor de eventos, que enviará uma mensagem para a fila nomeada: mensagens a cada segundo.
E da mesma forma iremos criar nosso consumer.js para consumir as mensagens da fila:
Baseado nos snippets acima, estamos “habilitados” para escalar as mensagens em N consumers.
Rodando ambos ao mesmo tempo, teremos algo como:
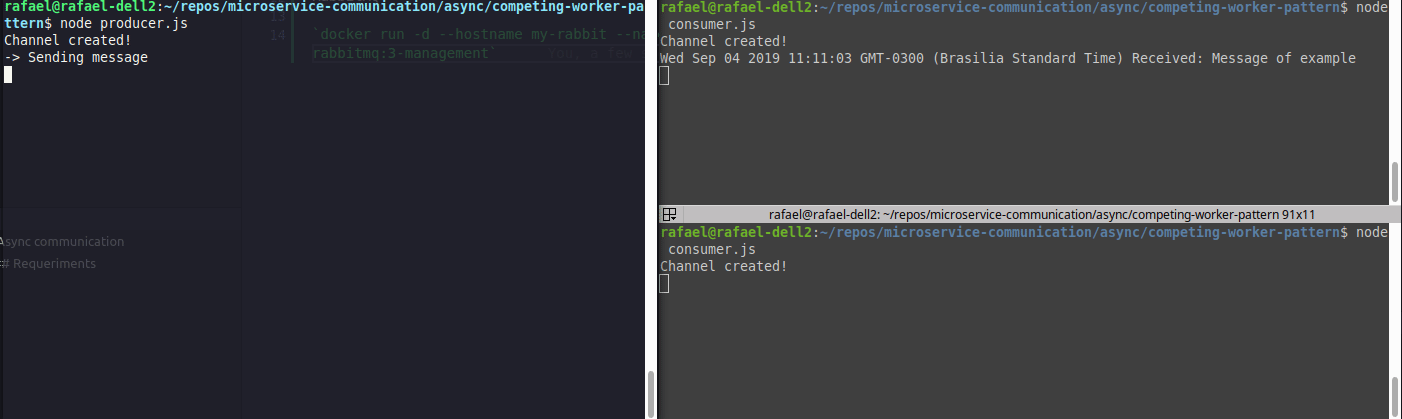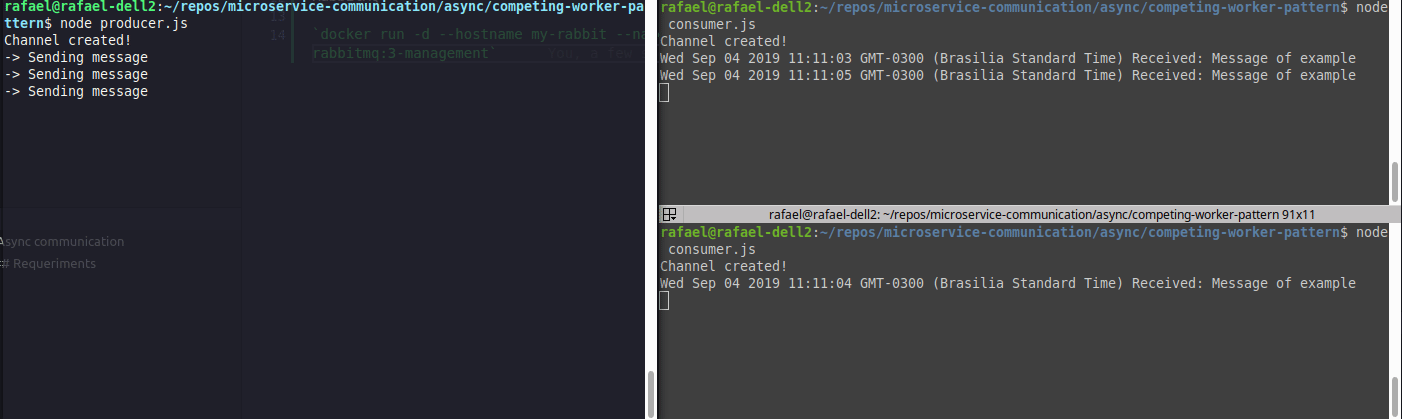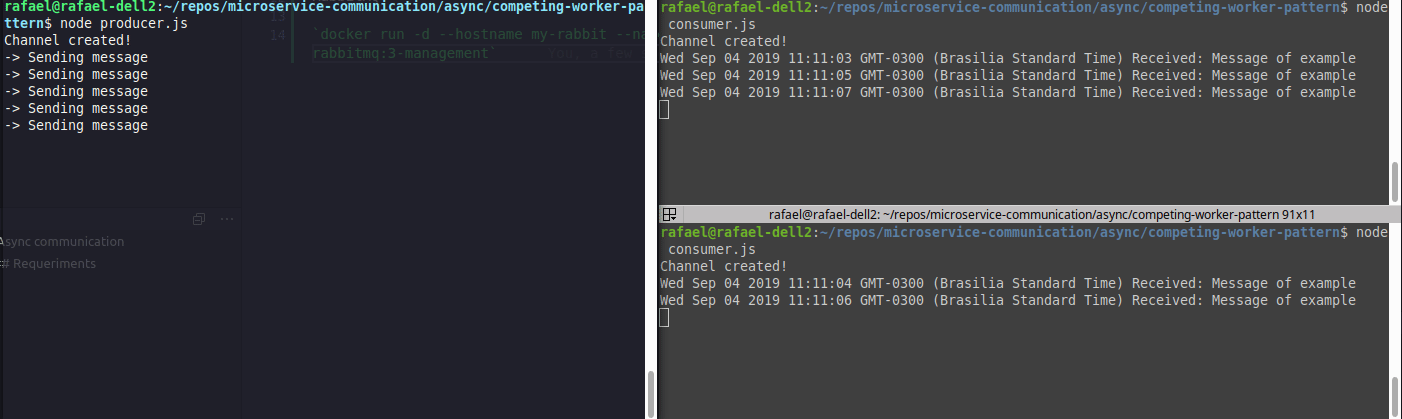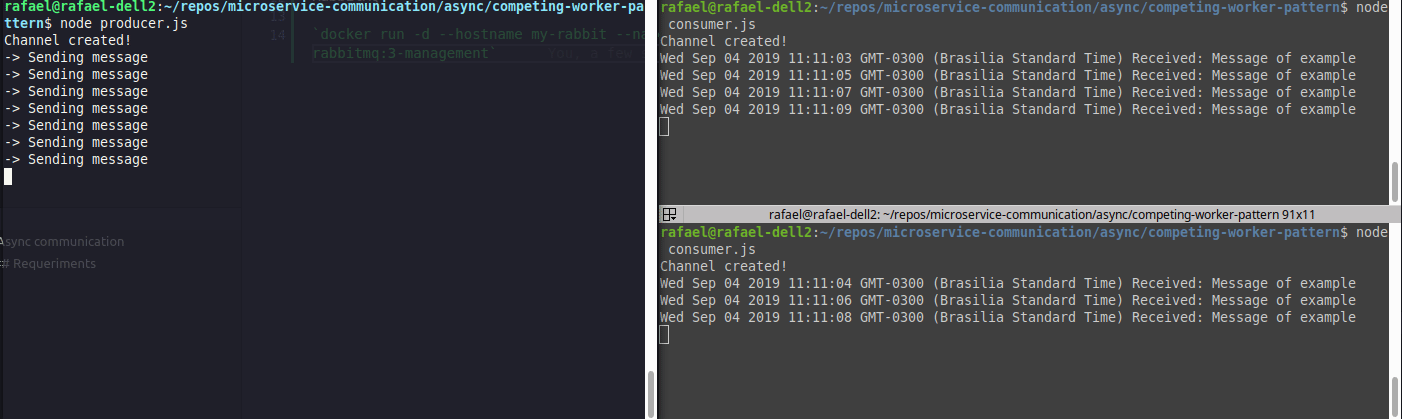 Exemplo de load balancer (competing consumers)
Exemplo de load balancer (competing consumers)
Perceba que as mensagens são divididas entre os consumers.
O código desse exemplo está aqui. Se quiser saber mais sobre esse padrão, este é um bom start.
Topics Pattern
Enviar eventos diretamente a uma fila é simples e fácil, porém quando a arquitetura cresce, novos patterns são necessários.
Imagine que seja necessário emitir um evento para mais de uma fila — “Ah, basta colocar o nome da fila e enviar!” — Infelizmente não é assim que a banda a toca. Definir filas e enviar acaba deixando sua aplicação acoplada! Ideal seria enviar somente para uma “fila” e ela trataria de encaminhar determinado evento para sua respectiva fila/consumer, certo? Pra isso existem os Topics Pattern!
Imagine um cenário aonde é enviado logs da sua aplicação para uma fila qualquer… em um primeiro momento, vai funcionar perfeitamente bem, porém, no futuro imagino que seja necessário aumentar a granularidade desse log e enviar baseado nos níveis de log (debug, warning, critical).
Quebrar os logs por níveis pode fazer com que aumente a flexibilidade de sua aplicaçao.
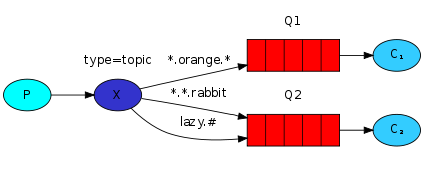
Eventos emitidos para um topic deverá conter um argumento chamado routing_key que deverá ser uma lista de palavras separadas por ponto(.). Exemplo: log.warning ou log.critical . Portanto, um evento enviado ao topic exchange será entregue a todas as filas na qual de “match” com o routing_key passado.
Imagine que temos 3 filas:
-
warning.logs — Responsável por processar alguma regra de negócio quando receber um Warning Log, portanto, seu bind será log.warning.
-
critical.logs — Responsável por disparar alertas quando receber um Critial Log, portanto, seu bind será log.critical.
-
logs — Responsável por salvar qualquer tipo de log, então seu bind será log.. O asteristico() indica que pode ser substituído por uma palavra qualquer.
Há também o # para bind, que pode ser substituído por zero ou mais palavras.
Segue um exemplo de dois consumers(canto direito) e um producer(canto esquerdo), onde o consumer1.js(canto superior direito) irá aguardar somente eventos #.critical.# e o consumer2.js(canto inferior direito) irá aguardar todos eventos
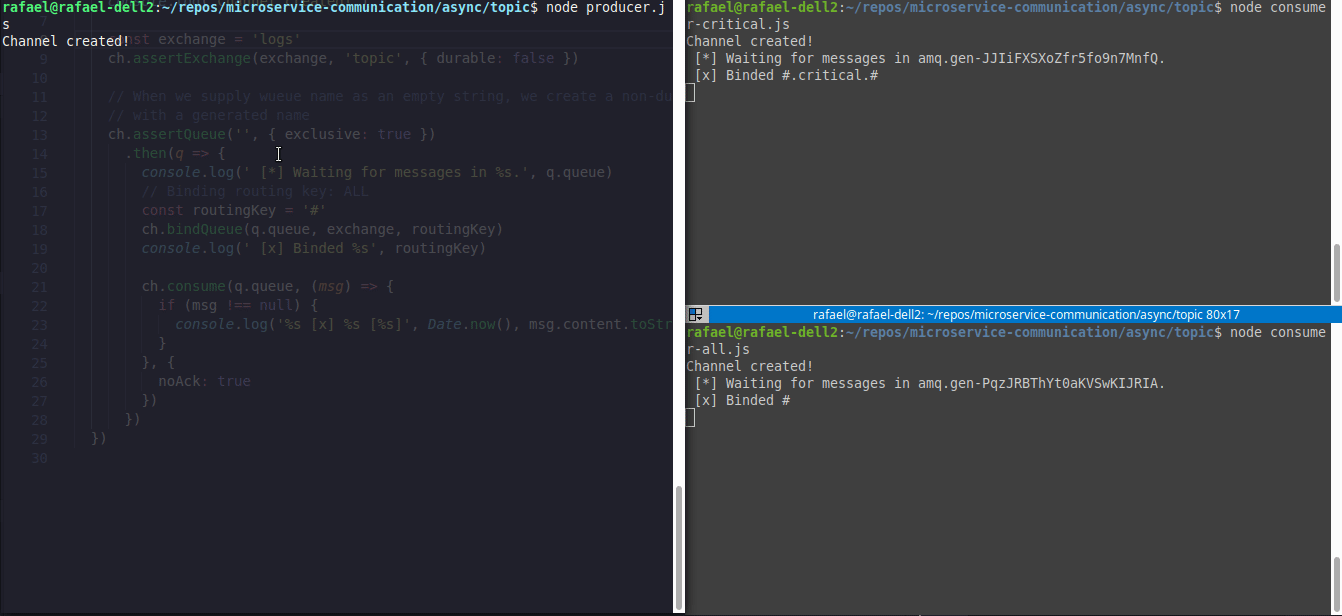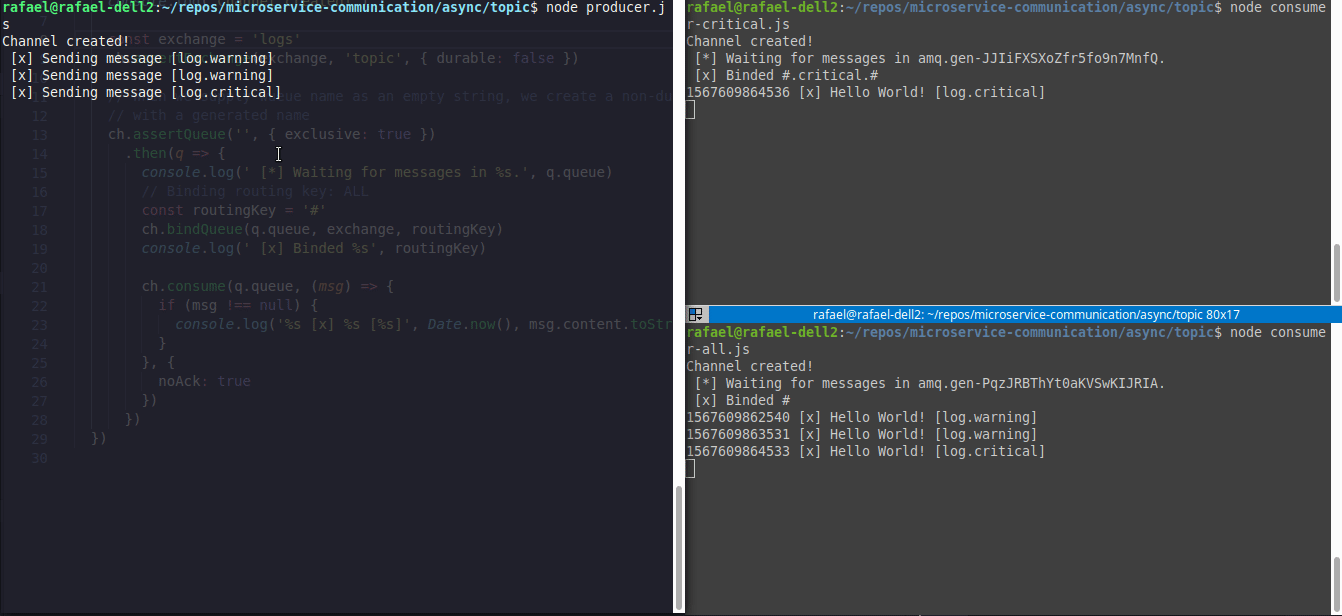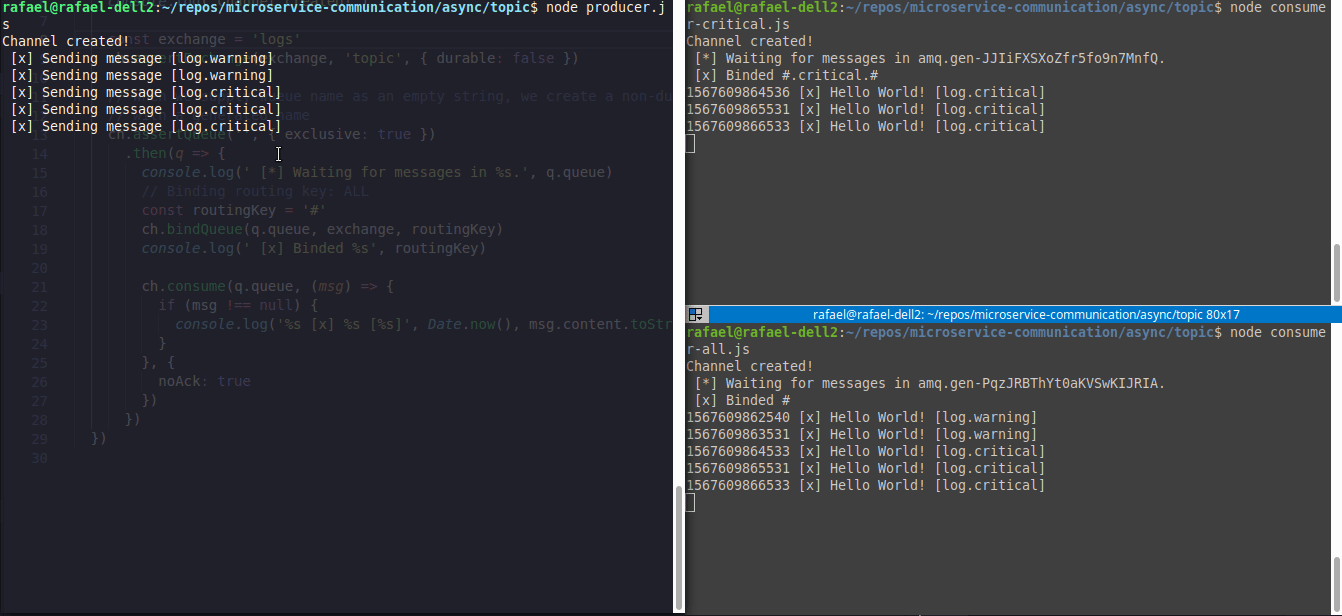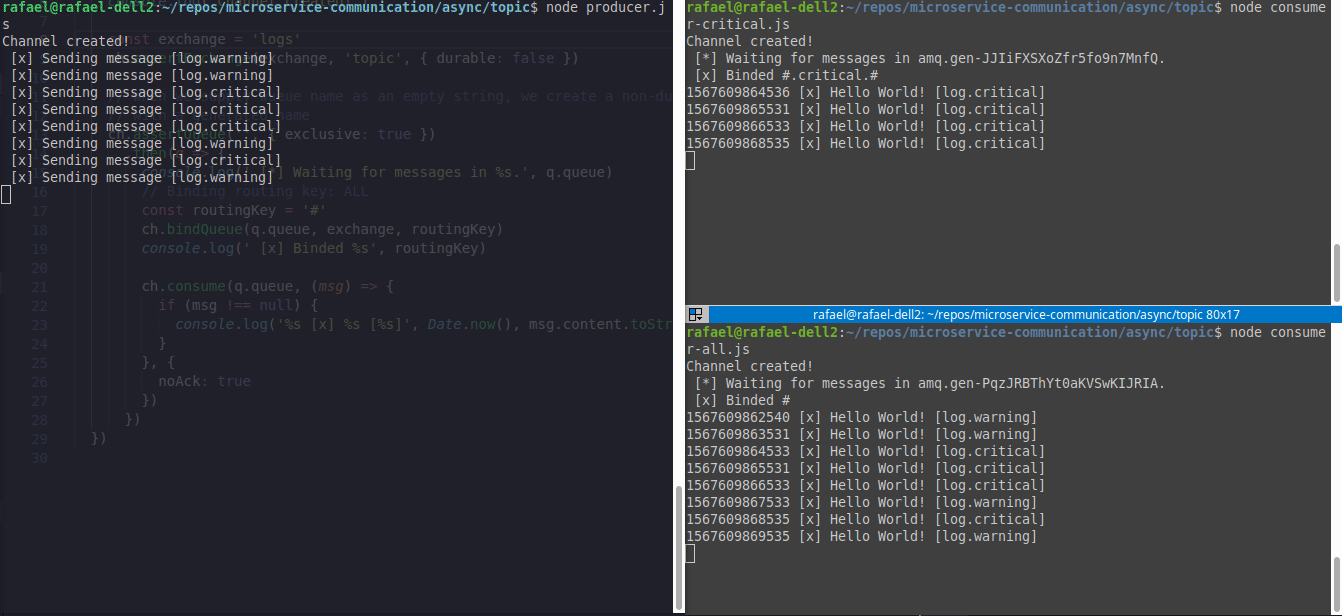
O código desse exemplo está aqui
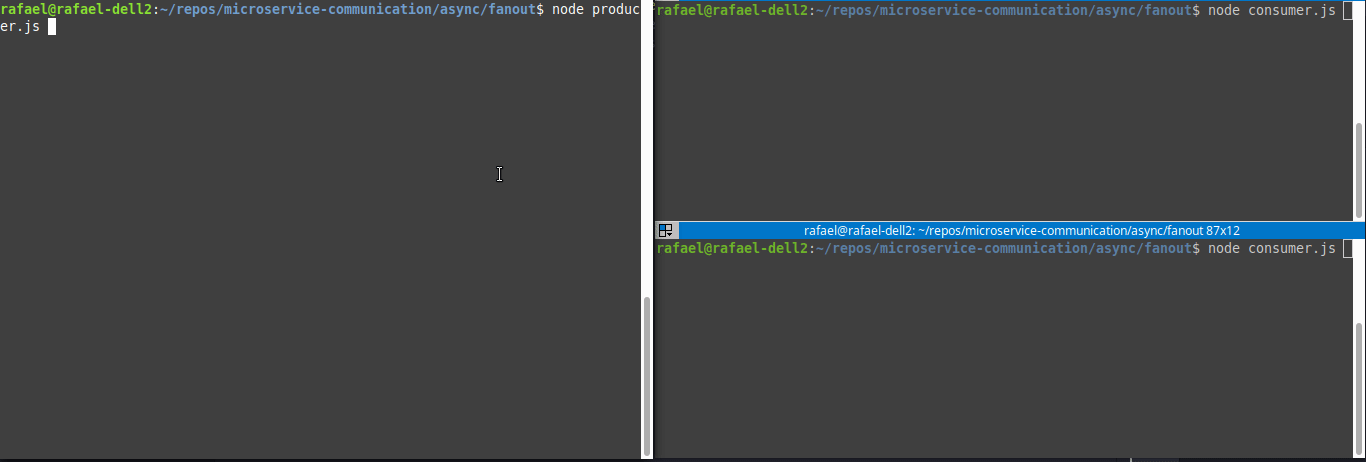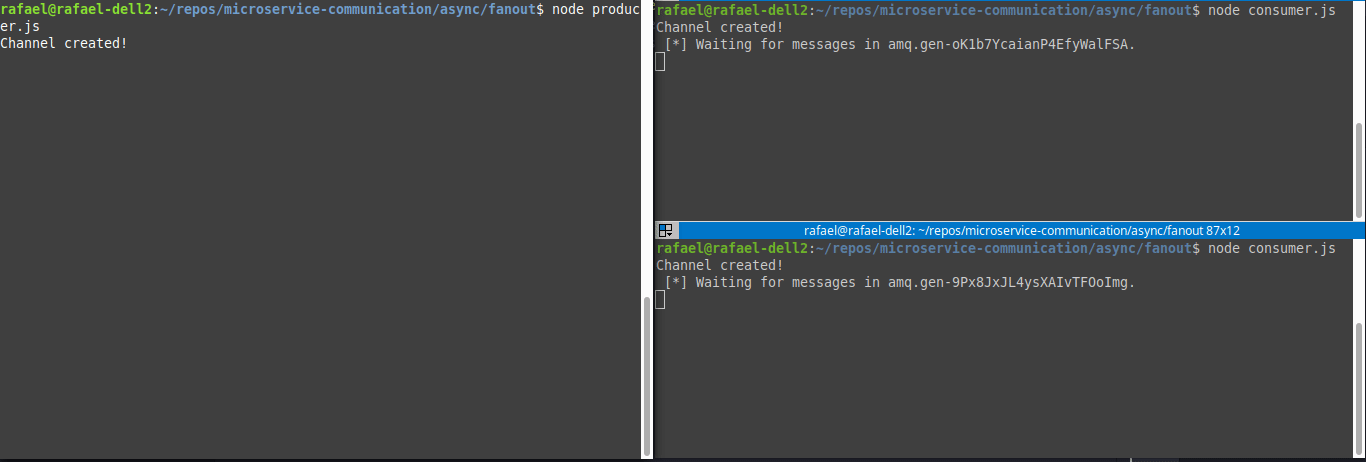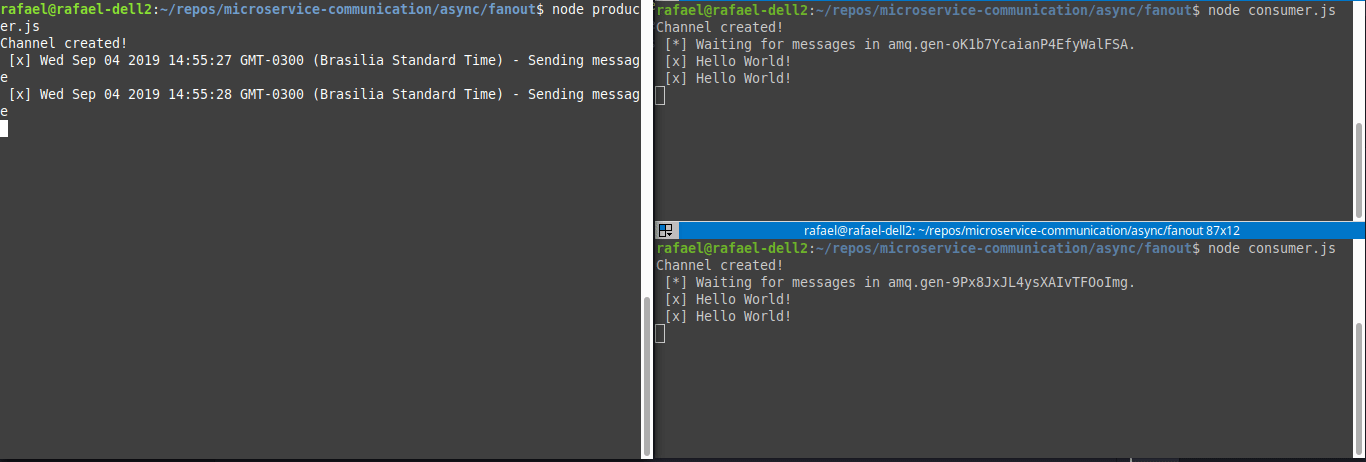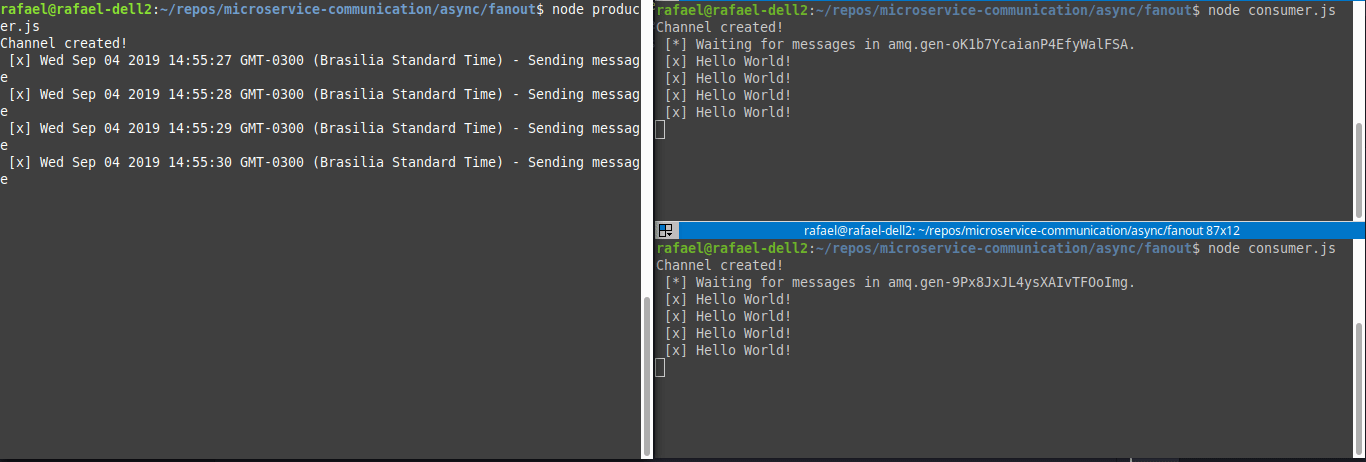
Fanout Pattern
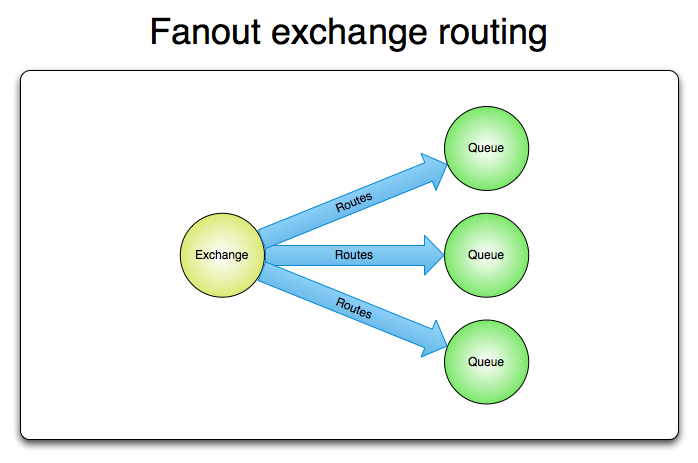
Topics nos deu uma flexibilidade e tanta. Porém, da forma apresentada, ele continua seguindo o Pattern Competing Workers. E se quiséssemos fazer o broadcast desse evento para várias filas?
Esse Pattern é muito usado não só com message brokers e sim na arquitetura de microservicos no geral, vale conferir!
Ao propagar uma mensagem para um fanout exchange temos a flexibilidade de escalar uma mensagem sem precisar especificamente criar uma fila pra isso. Isso nos permite lançar um evento no qual será processado por todos consumers que estiverem ouvindo a queue ou exchange.
Tomando como exemplo um e-commerce, ao finalizar uma venda precisamos fazer duas diferente tarefas:
-
Processar a venda ao financeiro
-
Enviar ao serviço de pagamento

E aqui um exemplo da aplicação rodando, o código fonte dela você pode conferir aqui.
RPC Pattern
](https://cdn-images-1.medium.com/max/2000/1*vkYkMgb7KYl3qZiAVX9SOA.png) fonte: http://alvaro-videla.com/2010/10/rpc-over-rabbitmq.html
fonte: http://alvaro-videla.com/2010/10/rpc-over-rabbitmq.html
Ao enviar uma mensagem assíncrona, boa parte das vezes enviamos ações e não questões. Porém, há cenários onde será necessário requisitar algum recurso e “aguardar” por uma resposta; pra isso existe um pattern bastante conhecido chamado Remote Procedure Call ou simplesmente RPC.
Vamos imaginar um cenário aonde será necessário requisitar um usuário de um microserviço RPC baseado em seu ID.
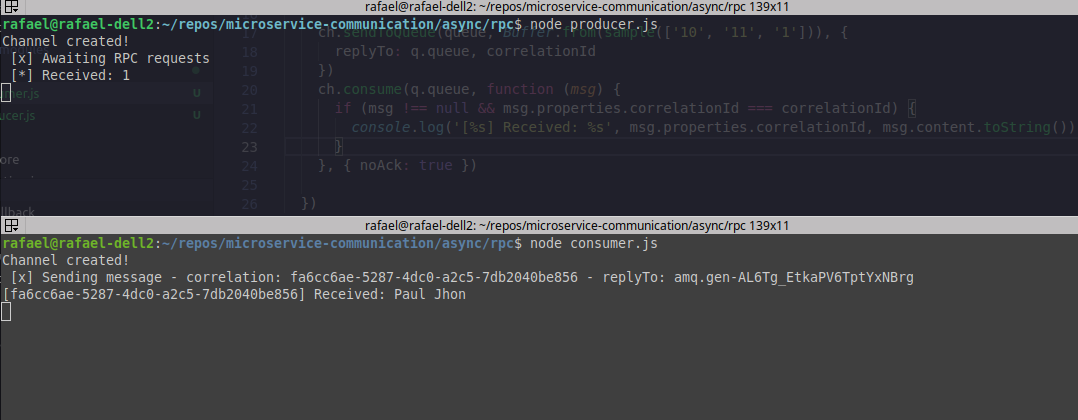
Tendo como base a image acima:
-
Producer — Serviço de usuário, no qual estará aguardando requisições RPC para assim responde-las.
-
Consumer — Serviço no qual tem usuário como dependência, enviará o ID do usuário requisitado para receber o nome do mesmo.
Veja que o producer recebeu um ID: “[] Received: 1” e assim, o consumer recebeu o nome do usuário requisitado: “[uuid] Received: Paul Jhon” portanto o processo de request/reply* funcionou perfeitamente.
Bom… Imagino que tenha surgido algumas dúvidas:
-
O que é o UUID?
-
O que é o replyTo?
Ao enviar uma questão assíncrona tambem recebemos uma resposta assíncrona e como saber a correlação entre a pergunta número 1 e a resposta número 1? Na comunicação assíncrona dificilmente você conseguirá garantir que as mensagens cheguem em sua ordem natural (1, 2, 3… 99). É nisso que o correlation_id é usado, ele será a ligação entre a pergunta número 1 e a resposta número X.
Agora, voltando a imagem de exemplo acima, enviamos uma mensagem com o UUID/correlation_id fa6cc6a2-XXXXX-856 e recebemos a resposta contendo o mesmo correlation_id, portando, temos a garantia que esse resposta seja referente a questão acima.
E o replyTo?
Bem, ele é o nome da fila no qual será enviada a resposta. Um microserviço que aguarda requisições RPC não deve ter uma fila de respostas, pois as perguntas podem vir de varios outros serviços. Sendo assim, ao receber o parâmetro replyTo ele saberá pra qual fila responder. Um simples callback queue.
O código desse exemplo você encontra aqui.
Considerações finais
Nesse artigo, tentei abordar de forma mais teórica possível a comunicação entre microsserviços com RabbitMQ, mas caso sinta falta de linhas de código, eu criei um repositório com todos os code examples que utilizarei nessa série. Basta clicar aqui.
Lembrando… a documentação do RabbitMQ é excelente e super simples! Vale conferir.
Redes sociais: Github, Twitter