Microsservicos Autonomos - Outbox Pattern
Em uma arquitetura de microsserviços boa parte de sua complexidade está na consistência dos dados, ou seja qual a melhor forma
de comunicar os microsserviços de forma que um consiga dados do outro? Como expor em um single endpoint a relaçao entre um recurso e outro?
Como lidar com 2PC/Saga? Veja isso e mais no Domingo Espetacular neste artigo.
Bom, antes de adentrarmos nas nuances da solução para as perguntas acima, vamos entender qual é realmente o problema enfrentado.
O Contexto
Quando se utiliza uma arquitetura voltada para microsserviços, normalmente o primeiro fato que nos vem a cabeça é separar os serviços por domínio, ou seja, tomando como exemplo um ecommerce, poderiamos ter um microsserviço de Users e outro de Orders. Portanto, vamos imaginar esse cenário.
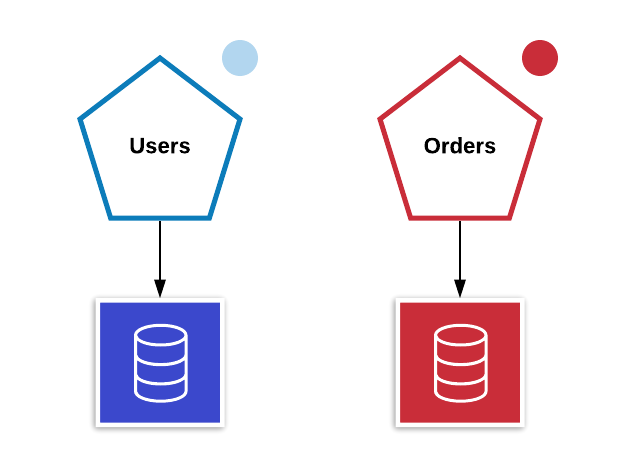
O Problema
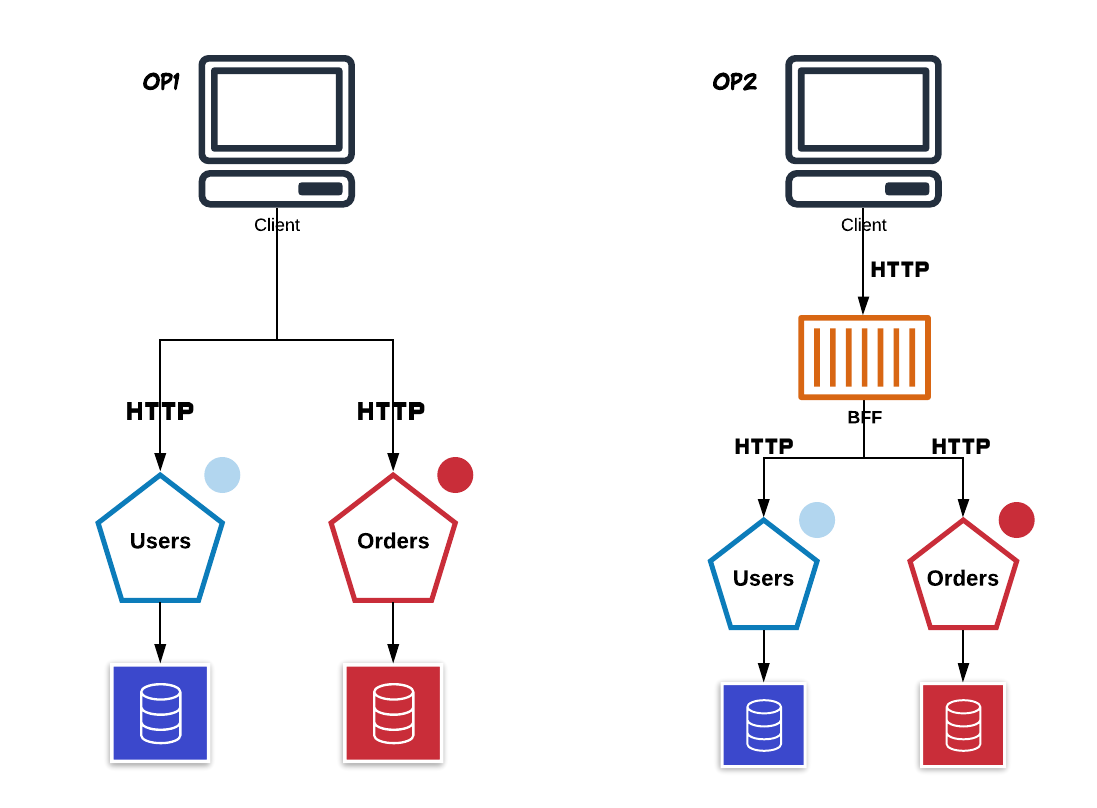
Imagine uma situação onde é necessário retornar a relação entre users e orders. Normalmente haverá dois possíveis meios:
- Realizar dois requests (um para capturar usuários e outro para capturar as orders de cada um.)
- Criar um BFF (Backend For Front-end) que faça o passo acima
Porém, e se nossa regra de negócio for que para cada novo user precisemos criar uma nova order?
“Mas isso é fácil, é só propagar um evento no message broker quando criar um usuário”
Boa! Mas, se o processo de criar uma order falhar, o usuário também deve ser removido…
“É só usar o Pattern Saga“
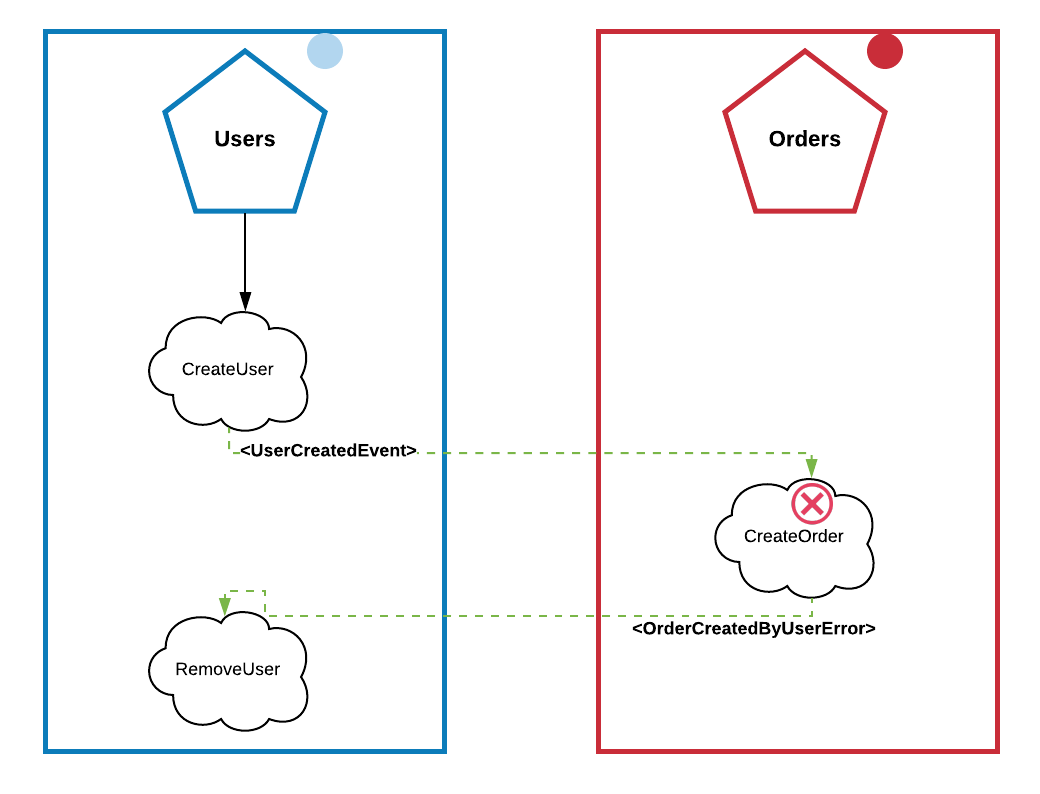
Bom, se você precisar concatenar outros serviços nessa regra sua arquitetura vai ficar com uma complexidade exponencial. Pra isso existe o Pattern Outbox; ao decorrer desse artigo, vamos entender porque lidar com consistência eventual é bom e te permite escalar em um domínio cheio de regras de negócio.
Microsserviços normalmente possuem seu próprio local data store, em nosso contexto, Users possuí sua database, assim como Orders. Entretanto, no exemplo acima lidamos com dual write, ou seja, a simples criação de usuários pode levar a possíveis inconsistências. O motivo é que não podemos ter uma transação compartilhada que abranja o banco de dados do serviço, bem como o Message Broker, pois o último não pode analisado em transações distribuídas. Portanto, em circunstâncias infelizes e possíveis, pode acontecer que seja criado o novo usuário no banco de dados local, mas não tenha enviado a mensagem correspondente ao Message Broker (por exemplo, devido a algum problema de rede). Ou, ao contrário, podemos ter enviado a mensagem para o Broker, mas não conseguimos manter o usuário no banco de dados local.
Ambas as situações são indesejáveis; isso pode fazer com que nenhuma order seja criada para um usuário aparentemente criado com sucesso. Ou uma order é criada, mas não há nenhum vestígio sobre o usuário de compra correspondente no próprio serviço de users.
Lembre-se: Um dos principais conceitos de microsserviços é a resiliência, portanto, se seu serviço depende de outros para “funcionar”, não há uma arquitetura de microsserviços, e sim uma arquitetura microlítica como chamo carinhosamente.
Teorema CAP
Este Teorema afirma que é impossível que o armazenamento de dados distribuídos forneça simultaneamente mais de duas das três garantias seguintes:
- Consistência
- Disponibilidade
- Partição tolerante a falhas
Consistência
Uma garantia que cada nó em um cluster distribuído retorne a escrita mais rescente. Consistência refere-se a cada cliente ter a mesma visualização dos dados. Existem vários tipos de modelos de consistência. A consistência no CAP (usada para provar o teorema) refere-se à linearizabilidade ou consistência sequencial, uma forma muito forte de consistência.
Disponibilidade
Cada nó que não falha retorna uma resposta para todas as solicitações de leitura e escrita em um período de tempo razoável. Para se considerar disponível, todos os nós (em ambos os lados de uma partição de rede) devem responder em um curto espaço de tempo.
Partição tolerante a falhas
Um sistema que é “partição tolerante a falhas” pode sustentar quaisquer quantidade de falhas na rede que não resulta em uma falha na rede completa. Os dados são replicados entre os nós/rede para manter o sistema ativo por interrupções intermitentes. Ao lidar com sistemas distribuídos modernos, a Tolerância de Partição não é uma opção, é uma necessidade. Portanto, temos que negociar entre consistência e disponibilidade.
Escolhendo
Consistência + Disponibilidade: Comumente utilizado em sistemas que necessitam de forte consistência e alta disponibilidade, chamados também de abordagem Otimista, pois partem do pressuposto que as escritas NUNCA falham.
Consistência + Partição Tolerante: Sistemas que optam por essa estratégia, precisam abrir mão da disponibilidade. Existe uma palavra, bastante importante nesse contexto, chamada: Conscenso. Em sistemas do tipo CP, caso exista um particionamento a escrita – como mencionado anteriormente, pode sim ser rejeitada/negada.
Disponibilidade + Partição Tolerante: Utilizado quando a necessidade maior é disponibilidade e escalabilidade, portanto, abrindo mão da consistência, lidando com a famosa Consistência Eventual, ou seja, deixando seus dados serem consolidados entre nós indefinidamente. – Será sobre essa escolha que vamos discorrer.
Youtube Use Case
O Youtube precisa mentir para seus usuários, e explico o porque. Quando lidamos com a massa de dados que o Youtube possuí, falar em escalabilidade é uma das tarefas mais difíceis, portanto, seguindo o Teorema CAP, devemos optar por Disponibilidade e Partição Tolerante sem titubiar. Pois, imagina centralizar os dados em um local só ou fazer com que eventualmente apareça um erro na tela do usuário? Portanto, vamos a algumas opções óbvias:
- Compartilhar a mesma base de dados para quaisquer aplicação – E está será o eterno problema.
- Deixar um servidor processando as requisições para recuperar os dados. – E este servidor será o problema.
- Manter mais de um servidor de dados, fazendo com que eventualmente os dados sejam consolidados entre todos os servidores. – Winner
É por isso que se duas pessoas entrarem em um vídeo em alta ao mesmo tempo irão ver visualizações com números distintos (claro, se cairem em nós distintos).
“Mas como lidar com a Consistência Eventual, e se precisar do dado atualizado?”
Bom, como dito anteriormente, nada é uma bala de prata, tudo depende do problema arquitetural a se resolver. O Domínio Users sempre contará com o dado atual como se fosse o mais recente, afinal ele não conhece outros domínios. Portanto, se por alguma razão seja necessário obter os dados em TEMPO REAL pode ser que esta abordagem não sirva para a resolução do problema – Mas cá entre nós, na maioria das vezes não é necessário nem escalável tal necessidade.
Consistência Eventual
“Eventual consistency is a consistency model used in distributed computing to achieve high availability that informally guarantees that, if no new updates are made to a given data item, eventually all accesses to that item will return the last updated value. Eventual consistency, also called optimistic replication, is widely deployed in distributed systems, and has origins in early mobile computing projects. A system that has achieved eventual consistency is often said to have converged, or achieved replica convergence. Eventual consistency is a weak guarantee – most stronger models, like linearizability are trivially eventually consistent, but a system that is merely eventually consistent does not usually fulfill these stronger constraints.” – Wikipedia
A ideia desse padrão é que quaisquer informações que o serviço X necessite contenha em seu próprio domínio. Em nosso contexto, vamos imaginar que precisamos do nome completo do usuário ao criar uma Order, portanto, para o domínio Order usuário é apenas um conjunto de name onde entra o chamado Bounded Context.
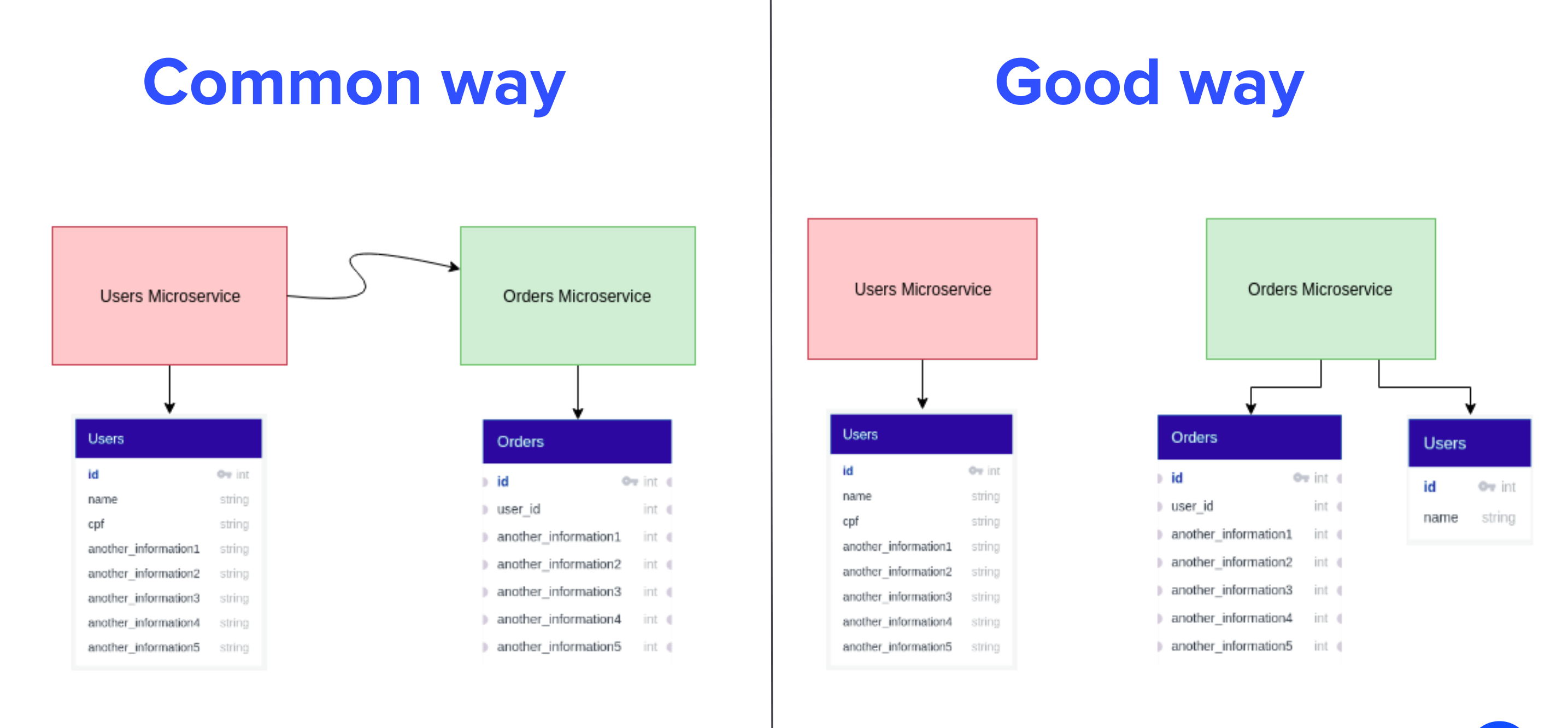
Perceba que os dados estarão replicados em ambos serviços (email, full_name), e isso é bom! Dessa forma garantimos a consistência local e temos a clamada transação local.
Consolidandos os Dados
Idealizamos, e agora?
Agora, apresentarei o famigerado Debezium e seu poder de CDC (Change Data Capture)
A ideia do Debezium é simples, ele atua no topo do Apache Kafka, ou seja imagine uma trigger de inserção na base de dados, escutando quaisquer mudanças na tabela (dependendo da configuração) e as replicando no broker. Ou seja, por definição expomos os dados que quisermos – Amplamente utilizado uma table outbox com o schema abaixo ref
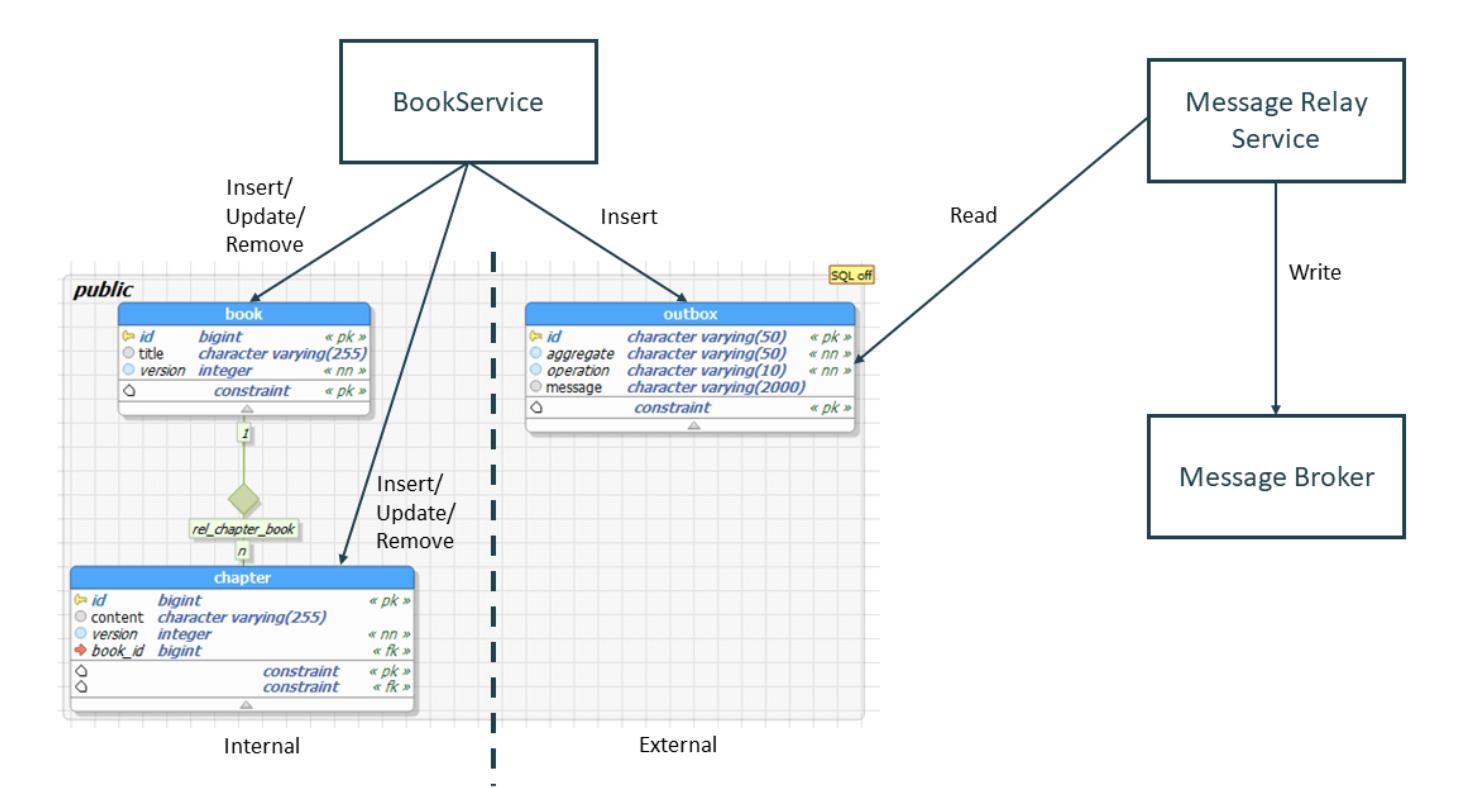
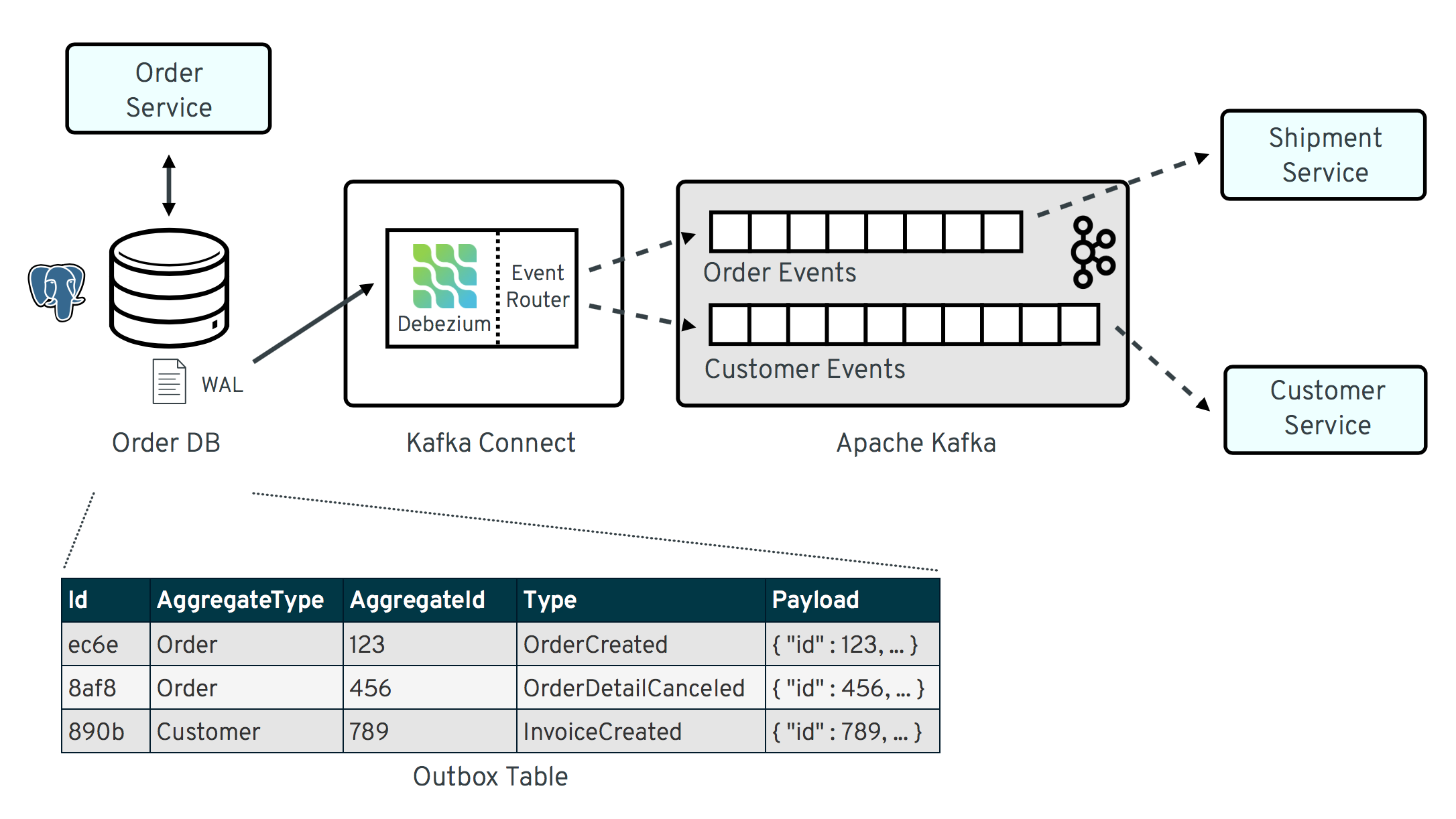
Não me prolongarei sobre como o Debezium faz, pra isso existe sua excelente documentação.
Para mostrar na prática, fiz um exemplo bem simples aqui basta seguir as instruções do README, e voilà!
Qualquer dúvida, fale comigo em qualquer rede social.