Network Performance in Real-world
Everybody knows or must know the famous statement: “Network is not reliable”. In fact, it’s true, however, it doesn’t means that you shouldn’t optimize it.
If you got here by yourself, likely you understand why performance matters in the business. Otherwise, I recommend you to read the first section of my previous blog post Performance Methodologies.
In this post, I’m going to talk a little more about the impacts of performance in the business. Mainly about network performance, however, keep in touch that probably I will talk about other fields of optimization in further posts.
The network latency is the room that is up to several optimizations, but first what’s latency and how this affects the customer experience?
Latency is the time elapsed from a package by a client to a receiver.
Before any performance optimization, we should define clearly our goal and the boundaries. This step is valuable to understand the client’s perception around the speed.
The average human reaction time is around 200 milliseconds following Human Benchmark Project, that’s a pretty interesting project, and following the “Mental chronometry”:

“Human response times on simple reaction time tasks are usually on the order of 200 ms. The processes that occur during this brief time enable the brain to perceive the surrounding environment, identify an object of interest, decide an action in response to the object, and issue a motor command to execute the movement. These processes span the domains of perception and movement, and involve perceptual decision making and motor planning. Many researchers consider the lower limit of a valid response time trial to be somewhere between 100 and 200 ms, which can be considered the bare minimum of time needed for physiological processes such as stimulus perception and for motor responses.”

And it’s also confirmed by the book HTTP Network Performance - Ilya Grigorik:
“Once the 300 milliseconds delay threshold is exceeded, the interaction is often reported as “sluggish” and at the 1000 milliseconds barrier, many users have already performed a mental context switch while waiting for the response. The conclusion is simple: to deliver the best experience and keep our users engaged in the task at hand, we need to be fast!”
In business, it transposes usually to a better conversation rate:
- Mobify found that decreasing their homepage’s load time by 100 milliseconds resulted in a 1.11% uptick in session-based conversion.
- Retailer AutoAnything experienced a 12-13% increase in sales after cutting page load time by 50%.
- Walmart discovered that improving page load time by one second increased conversions by 2%

Common issues
In the network, there are several cases that can affect the latency:
- The route that your ISP uses to reach the server
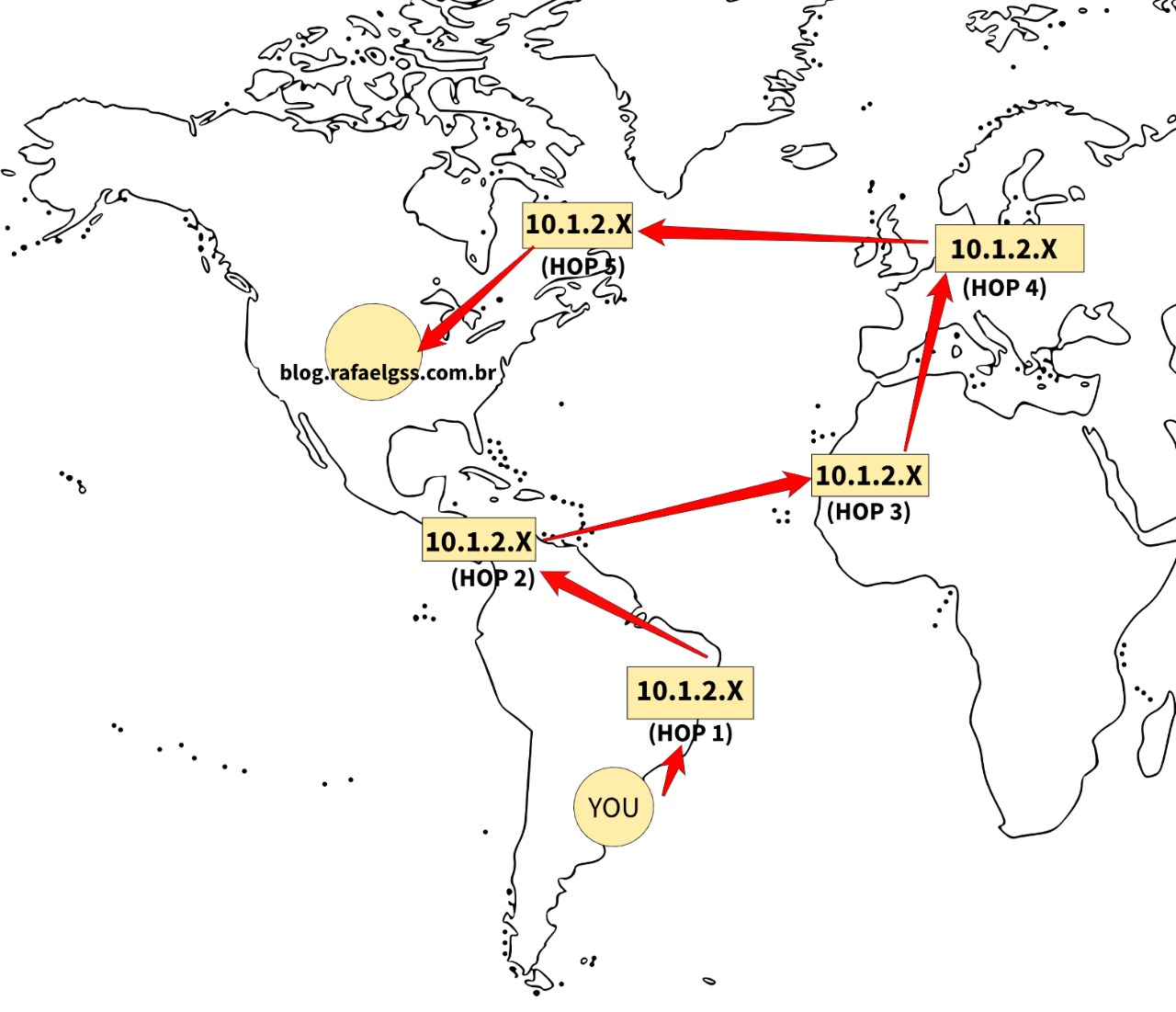
Eventually the ISP does not provide the best path (latency wise) to reach the end server, it’s due to several factors and varies depending on ISP. In fact, is not uncommon to see gamers angry because of their latency in the game even with a good bandwidth contract.
- The distance between the application server and the client

This information is obvious, however, I’ve seen a lot of architects ignoring it. When the server is far away from client it needs more hops to reach and consequently latency.
Client Bandwidth is not enough!
Most of people tends to believe that the reason of delay is often the client bandwidth, in fact, it helps for sure, but as you will see, it’s not a determinant factor of improvement.

Once the client reaches 5Mbps approximately, they may not see too much improvement in page load time, on other hand, reducing latency will always improve the loading time.
This happens because the majority of latency is caused by Three-Way Handshake in HTTP/1.1.
In fact, the vast majority of traffic around the web is still HTTP/1.1, and it means that for every communication between client-server the workflow performs Three-Way Handshake and it introduces a full roundtrip of latency (RTT).

A common way to measure the RTT is:
$ ping -c 10 SERVER
...
rtt min/avg/max/mdev = 195.933/197.576/198.423/0.912 ms
Cloudflare or another proxy will hide the real RTT, the result performed by ping is only to Cloudflare servers, in those cases, I recommend you to ping directly the webserver IP if available.
Improve HTTP/1.1 communication
Well, at this point I’ll assume that the reader understands what is the impact of performance in applications and has set up their boundaries and goals.
Obviously, the application monitor is up to the reader to define, it is out of context for this article, so make sure that before any optimization you have the proper tools to measure it.
For web applications, I strongly recommend a tool such as https://www.webpagetest.org/ to give insights before any early optimization.
Remember: The best TCP communication optimization is avoid to send unnecessary packages.
The main browsers nowadays limit HXR requests by domain and commonly the limit is set to 6 connections per domain. For HTTP/1.1 this statement is very important since for every resource requested (CSS, JS, Images) uses an connection. It means that when the client uses HTTP/1.1 connection they are able only to fetch 6 resources in paralellel.
Since the limit of connection is per domain, a well adopted approach is to use domain sharding to serve multiple resources.
However, is important to notice that for every resource requests a RTT is added on the top.
Besides the TCP Normal workflow, the are are few adjustments up to do in order to optimize the HTTP/1.1 communication.
-
Use Connection Keep-Alive. By default in HTTP/1.1 the connection keep-alive is enabled by default, but if you are using HTTP/1.0 or prior (really!) make sure to enable the keep-alive. The keep-alive was back-ported to HTTP/1.0 and enabled by the header
Connection: Keep-Alive. TCP Connection reuse is critical to improving performance. - Send fewer bits (Sorry JSON API Spec lovers)
- Increase TCP CWND (Initial Congestion Window).
- Use CDN’s to locate the bits closer to the client.
- Upgrade the server kernel to the latest version.
- Compress transferred data properly.
Request Pipelining
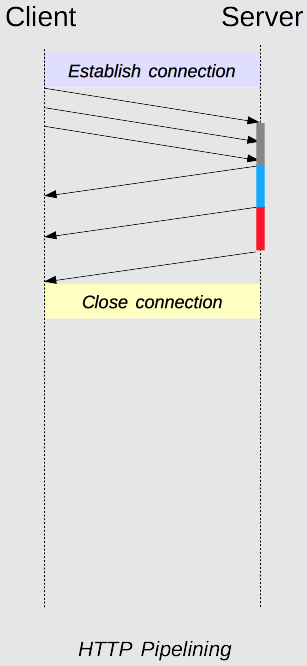
As mentioned in the above section the HTTP/1.1 stabilish a persistent connection between requests, said that, a common flow using a single TCP connection is:

Each HTTP request over the TCP connection must be responded to before the next request can be made. The request pipelining allows multiple HTTP request over the same TCP connection without waiting the previous request increasing the throughput considerabily.
 .
.
Pipelining is the process to send successive requests, over the same persistent connection, without waiting for the answer.
Pipelining requests looks a wonderful feature, but why does no client enable this by default?.
Teorically, pipelining looks awesome, but in the practice 90% of the cases is too much complexity handled for a “little” improvement.
HTTP clients should not pipeline requests that have side effects (such as POSTs). In general, on error, pipelining prevents clients from knowing which of a series of pipelined requests were executed by the server. Because nonidempotent requests such as POSTs cannot safely be retried, you run the risk of some methods never being executed in error conditions.
HTTP Pipelining may also increase drastically the chances of HOL problem. That said, before implement it, make sure of all the risks of pipelining requests.
HTTP/2
The HTTP/2 was released in 2015, however, it’s difficult to be fully available to all clients as it does not depend entirely on the applications, such as any protocol, both (client and server) must be able to speak the same language.
However, applications are fully capable of communicating with others applications via HTTP/2, and this is strongly recommended. In this section, I will cover the key improvements of HTTP/2.

Request Multiplexing: HTTP/2 can send multiple requests for data in parallel over a single TCP connection. This support enables a conversation end-to-end without creating several sockets to receive and request resources. The workaround to use domain sharding is not needed when using HTTP/2 and later.
Header compression: Compressing headers reduces the bytes transmitted during a connection. For instance, a customer is visiting an website to purchase a gift. On a low bandwidth network, especially one not using header compression, the response time from the server is longer, and the website renders slowly at customer end.
Using HTTP/2 which deploys the HPACK format for header compression, the pages will load faster with better interactive response time. The header needs to be sent only once during the entire connection leading to a significant decrease in the packet header overhead.
Binary Frame: The binary framing layer is responsible for all performance enhancements in HTTP/2, setting out the protocol for encapsulation and transfer of messages between the client and the server.
The binary framing layer breaks the communication between the client and server into small chunks and creates an interleaved bidirectional stream of communication. Thanks to the binary framing layer, HTTP/2 uses a single TCP connection that remains open for the duration of the interaction.
For a further read, check the references link.
Additional Considerations
HTTP/3 is the third and upcoming major version, currently under development. However, the HTTP topic would require an specific article about each one of those major versions. This article was created to show fields of improvement at network level and HTTP optimizations is one of the key improvements.
Acknowledgement
Zekth & gabriellamas for reviewing it.